Modern C++
Introducing Modern C++
C++标准
-
C++98 -
C++03 -
C++11 -
c++14 -
C++17 -
C++20Support in
gccis highly experimental, and will almost certainly change in incompatible ways in future releases.
C++特性
C++ v.s. C
| C++ | C |
|---|---|
| not a strict subset of C++ | |
| stronger type system | weak type system |
| high-level abstractions | only low-level memory abstraction |
powerful custom types (classes) | only data aggregation (struct) |
| use compiler as correctness checker | get the code to compile quickly |
| if it compiles, it should be correct | debugging is the real work |
C++ v.s. Java
| C++ | Java |
|---|---|
| ==value semantics for all types== | ==value semantics only for primitives (int, float,… )== |
| optional reference semantics for all types | baked-in reference semantics for class types |
| full control over memory (de-)allocation; no garbage collection | garbage collector; can degrade performance |
| deterministic & controllable object lifetime | no predictable object lifetime control |
| ⇒ memory frugal | ⇒ high memory consumption |
| aggressive inline can eliminate slow function calls | performance degradation due to un-devirtualizable, non-inlinable methods |
C++ v.s. Python
| C++ | Python |
|---|---|
| almost always faster | almost always slower (in practice around 25-50 times) |
| complex syntax and tons of features can be intimidating to newcomers | simple syntax; usually easy to comprehend |
| statically typed | dynamically typed |
| many types of bugs can be caught at compile time | many types of bugs will only manifest at runtime |
| suited for safety-critical large-scale systems | hard to build reliable large-scale systems |
| even simple, small-scope tasks can quickly require an expert knowledge of various arcane corner cases & quirks | tends to be more beginner-friendly and small scripts are usually quickly written |
| fairly small standard library but extensive ecosystem with libraries for nearly everything | ==batteries included philosophy== with tons of libraries only one import away |
https://isocpp.org/wiki/faq
数据类型
基础数据类型
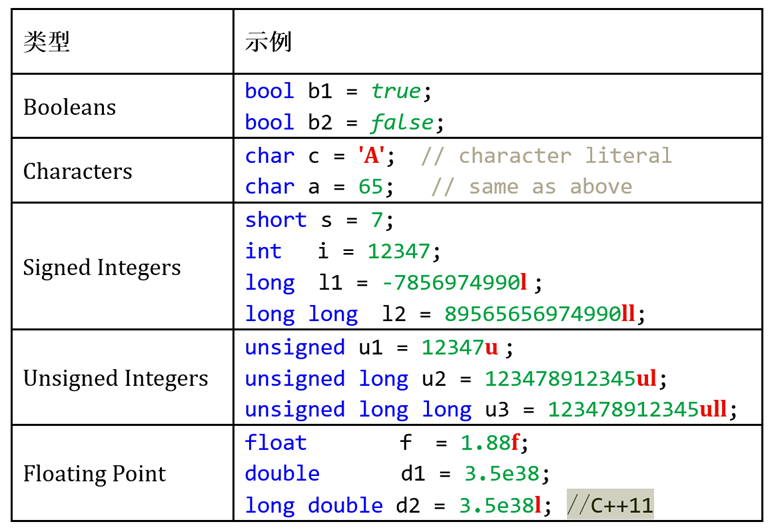
0is alwaysfalse;everything else istrue。
字符类型:char型(1字节),wchar_t型(长度与平台相关可能是2或4字节),char16_t(2字节), char32_t(4字节)。
字面值
字面值类型包括:整数常量、字符常量、浮点数常量、字符串常量。此处的常量均是指字面值常量。
整数常量
整数常量可以声明为十进制、八进制、十六进制,有无符号,长或短整型。十进制数以非零数字开始,八进制以数字“0”为前导,十六进制以“0x”为前导。
后缀“u”或“U”用于声明该数值为无符号数,未添加该后缀则表示有符号数。
后缀“L”或“l”用于声明长整形。
后缀“i64”或“ll”或“LL”用于声明64位整形。
浮点常量
浮点常量中是必须包含小数点的定点数,还可以包含指数,还可以附加后缀用于声明类型。浮点数默认类型为double,当添加后缀“F”或“f”表示浮点型,“L”或“l”表示long double(long double和double的长度都是一样的,但是类型不相同)。
定点数的表示方法:
double x = 18.46, y = 38. ;
指数表示方法:
double x = 18.46e0, y = 18.46E1 ;
指数部分可以是负数。当浮点数包含指数时,定点数部分可以不包含小数点。
数值范围:
#include <limits>
std::numeric_limits<double>::max() // largest positive value
std::numeric_limits<double>::min() // smallest value > 0
std::numeric_limits<double>::lowest() // smallest negative value
std::numeric_limits<double>::epsilon() // smallest difference
一个整型类型可以转换成更宽位数的整型类型,这种转换称为整型提升。进行这种转换不改变数据的值。
字符常量
字符常量是使用“'”包围的一个或多个字符。
如果整型使用普通字符常量或宽字符常量声明,则不足位补零;如果普通字符或宽字符用多字符常量声明,则将丢弃高位(左边的)字符。超过四个字符的字符常量声明将出错。
在字符声明中,具有特殊意义的字符(\、'、"等)需要使用转义字符“\”消除特殊意义。转义序列有三种类型:
-
简单类型:
\' \" \? \\ \a \b \f \n \r \t \v; -
八进制转义序列(转移字符之后最长三位八进制数,超过三位则第二个字符开始,或者从第一非八进制数字结束):
\012; -
十六进制转义字符:转义字符后接“
x”,其后接十六进制数字,后接数字位数无限制,只能以非十六进制数字结束。十六进制转义字符首先去除多余的高位,然后将剩余的8位数字转换为整型,再将整型转换为字符,如果整形的无符号值大于255,则转换不能完成,编译时会出错。转移字符之后的字符如果不是特殊字符,则结果由具体的实现决定。
双引号在字符常量中可以不使用转义字符。
Microsoft Specification:通常只能是ASCII字符,包括96个字符:空格、水平制表符、垂直制表符、换行符、Formfeed和26个大小写字符、10个数字、以及下列字符:
_ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '对于转义字符之后的非特殊意义字符,非特殊字符将正常显示,而转义字符不会显示;编译时会出现警告“不可识别的字符转移序列”。
字符串常量
一个字符串常量由0个或多个字符构成,有双引号所包围,字符串代表一个由“null”结尾的字符序列。字符串中可以包含所有字符常量允许使用的字符,以及使用转义字符。C++字符串包含两种类型:char[],wchar_t[]。
wchar_t w[] = L"wide string";
声明
wchar_t字符或字符串常量需要添加一个前缀“L”,类似地u用于char16_t类型字面值,U用于char32_t类型字面值。通过指向常量字符串的指针修改常量字符串是不允许的,结果未知。
以空格分隔的字符串会被自动拼接为单个字符串(也可以在行末使用“\”连接两行。)。
const char* b = "first" "second" // ⇒ "first second"
原始字符转字面值:
char const * ch_array = R"(raw "C"-string c:\users\joe )"; // c++11
Microsoft Specification:在一些情况下,声明的相同的字符串将被合并为一个字符串,在内存中使用同一段内存。
字符串的字面值最大长度为2048字节,对于
char和wchar_t都一样。如果定义了UNICODE,则
_T()等效于前缀L。
枚举
限定作用域枚举,使用枚举类型名访问枚举成员。
enum class day:short { mon, tue, wed, thu, fri, sat, sun };
day d = day::mon;
非限定作用域枚举,不同的枚举类型不能包含相同名字的成员。
enum day { mon, tue, wed, thu, fri, sat, sun };
day d = mon;
可以为枚举指定底层整数类型(char, short, long,...,默认为int)。可以将枚举强制转换为其底层类型。
引用
引用声明以后就是绑定到变量的别名,对引用名再赋值等效于修改绑定变量的值,因此无法再修改引用本身(赋值)使之绑定到其他变量。由于引用是变量的别名,因此通过引用总是能访问有效的变量。
[const] ValueType [const] & ref_name = VarName;
const声明符可以位于类型的前面或后面,但后者与指针类型声明风格保持一致。references cannot be "null", i.e., they must always refer to an object
int i = 2, k = 3;
int& ri = i; // reference to i
ri = k; // assign new value to ri(i)
如果引用声明为常量,则无法通过该引用修改变量的值。
引用的应用
-
作为函数、“
[]”和“=”操作符的返回值,满足左操作数可以被赋值的要求(L-value)。Dangling Reference:
不要返回局部变量的引用;
引用容器元素在修改容器后可能失效;
-
作为函数参数,等价于使用指针进行参数传递,而无须复制实际参数。
-
在迭代循环中使用
for(std::string & s : v) { cin >> s; } // modify vector elements for(std::string const& s : v) { cout << s; } // read-only access for(auto & s : v) { cin >> s; } for(auto const& s : v) { cout << s; } -
Avoid Output Parameters! 难以确定参数是否发生变化,参数是否仅作为输出或还作为输入。
-
Just take returned objects by value. This does not involve expensive copies for most functions and types in modern C++, especially in C++17 and above.
使用引用绑定函数返回值将导致临时变量的生命周期变长。
引用绑定规则
Rvalues and Lvalues
左值(Lvalues):expressions of which we can get memory address
- 内存中可引用的对象
- 具有名字的对象 (variables, function parameters, …)
右值(Rvalues):expressions of which we can't get memory address
- 字面值(
123,"string literal", …)(位于代码区); - 运算的零时结果;
- 函数返回的零时变量;
左值引用:type&,仅能绑定到左值;type const&可绑定到const左值和右值;
右值引用:type&&,仅能绑定到右值(涉及类型推断的除外);
万能引用(转发引用):根据类型推断的结果,可能为左值或右值引用。
auto&& ref = var;
template<typename T> void f(T&& param);
类型推导是必要条件,被推导类型必须为
T&&,其中T是模板类型参数。
类型语法
类型别名
using NewType = OldType; // C++11
typedef OldType NewType; // C++98
类型推断
auto variable = expression; // c++11
类型转换
static_cast(v):强制类型转换,编译器允许执行(但不一定是自动执行的)的任何转换都可以完成。避免发生精度损失时的警告。类似于C语法type(var)。
const_cast(v):去除常量性质,是变量能够被修改。
dynamic_cast(v):运行时动态识别类型。将基类类型的指针或引用安全地转换为派生类型的指针或引用。
reinterpret_cast(v):对于编译器不允许的转换类型(如指针类型转换),可以使用reinterpret_cast进行强制转换而不产生编译期错误。
std:move(T&&)将参数强制转换为右值;
std:forward<T>(param):仅当实参为右值时,将形参转换为右值;
指针
指针可以用于访问对象,且可以在运行期间改变其引用的对象(引用则不能修改)。指针的一个重要用途是函数参数传递,使用指针可以进行地址传递,则主函数和子函数可以访问同一段内存的变量。
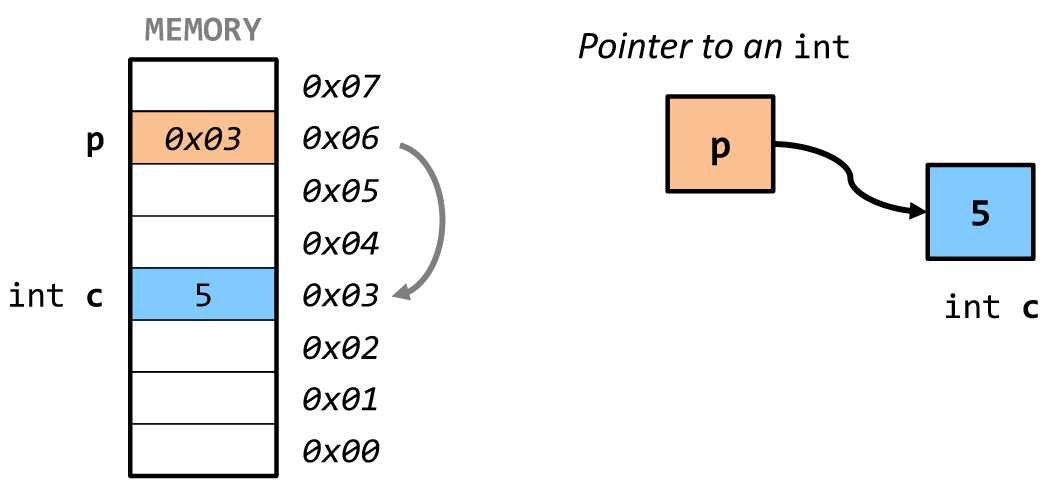
原始指针
指针存储内存地址的整数变量。通过取地址运算符&获取变量地址。
int a = 1;
int* ptr = &a;
或通过动态内存分配获取堆上创建的变量的地址。
指针运算
指针可以进行赋值运算、算数运算、关系运算和解引用运算。
*:对象引用运算符;
->:对象成员引用运算符;
point *p = new point{1,2};
cout << p->x << p->y << *(p).x;
优先使用引用,语法更加简洁。
智能指针(C++11)

unique_ptr
不能复制指针,但可以移动指针指向的对象到新的指针,原指针被置为nullptr。
#include <memory>
auto p = make_unique<Type>(init_list); // c++14, more safe
std::unique_ptr<Type> p1(new Type(args)); // c++14
auto p2 = move(p); // 不能复制unique_ptr
仍然使用
->运算符访问类型的成员。
shared_ptr
#include <memory>
auto p = make_shared<Type>(init_list); // c++14
std::shared_ptr<Type> p1(new Type(args)); // c++14
auto p2 = p;
引用计数:当最后引用对象的指针被销毁时,对象被销毁。
weak_ptr可以复制shared_ptr但不影响引用计数。
数组
type array[N];
type array[N] = {1,2,3,...};
当初始化列表给定时,可省略数组长度参数。==数组长度?==
动态创建数组:
type* ptr_array = new type[size];
type* ptr_array = new type[size]{1,2,...};
多维数组:创建$M\times N\times\cdots$维数组。
type array[M][N]...[];
type (*ptr)[N]... = new type[size][N]...;
仅有数组的最高维度是可以动态分配的,将其他维度整体看作一个整体(子数组)。
K维数组可以看成由size个维度为K-1的子数组构成的。分配一维数组,实际上是分配连续的size个基本变量;分配二维数组,实际上是连续分配size个一维数组,以此类推……动态创建数组时只有
size是变量,其他参数必须是编译期确定的常量(字面值或constexpr)。指向数组的指针进行“加减”运算,指针加减1实际对应的内存地址偏移量为对应子数组的内存占用长度。
指针数组
即数组元素是指针类型。指针数组的声明:
type* ptr_array[L1][L2]...;
type(*ptr_array[L1][L2]...)[M][N]...[P];
其中[L1][L2]...是指针数组本身的维度,而type(*)[M][N]...[P]代表最终指向的数据类型。如果带参数[M][N]...[P],则代表指向的是数组(的维度);如果没有该参数则为指向变量的指针(此时不省略()会生成警告)。
数组索引
array_name[index];
*(array_name+index);
数组名相当于指针常量。
高维数组在内存中实际上是按照线性方式存储数据的,所以实质上等效于是一个一维数组,所以仍然可以定义一维数组指针来访问数组元素。则指向第一个元素的一维数组指针的值应该是:
type *ptr = array[M][N]...; // 省略最后一维
type *ptr = &array[M][N]...[P]; // 或直接取元素地址
类型修饰符
静态变量
static int x = 1; // 定义静态(文件作用域)变量
extern int x; // 引用全局(非静态)变量,不推荐使用全局变量
可以在头文件中定义静态变量,引用该头文件的源文件将分别生成独立的文件作用域静态变量。
局部静态变量:静态变量定义在非全局作用域(如函数内部)。该变量的生命周期为程序生命周期,但仅能在定义该变量的作用域中访问。==局部静态变量只会在定义位置被初始化一次==。
全局变量构造器:在静态函数中返回静态变量的引用。
常量
Type const variable_name = value;
const Type variable_name = value;
用const关键字可以代替#define宏,使用const关键字声明的常量在编译时可以进行类型检查,而使用#define宏定义的常量则不能。
常量表达式
表达式的值在编译期间是确定的,其组成部分都是常量表达式。
constexpr int i = 2; // OK '2' is a literal
constexpr int cxf(int i) { return i*2; }
constexpr int j = cxf(5); // OK, cxf is constexpr
constexpr int k = cxf(i); // OK, cxf and i are constexpr
c++14:常量表达式函数内部可以包含多条语句;
常量相关指针
常量指针:指针本身是常量,即不能更改指针本身(所存储的内存位置),但可以更改指针指向的内容。
指向常量的指针:指针所指的内容必须是常量,不能修改指针所指的内容,但可以修改指针本身(所存储的内存地址)。可以用于函数参数,防止函数改变通过指针传入的参数。
type *const ptr; // const pointer to variable of Type <type>
type const *ptr; // pointer to const variable of Type <type>
type const *const:指针本身不能改变,指针所指的值也不允许改变。
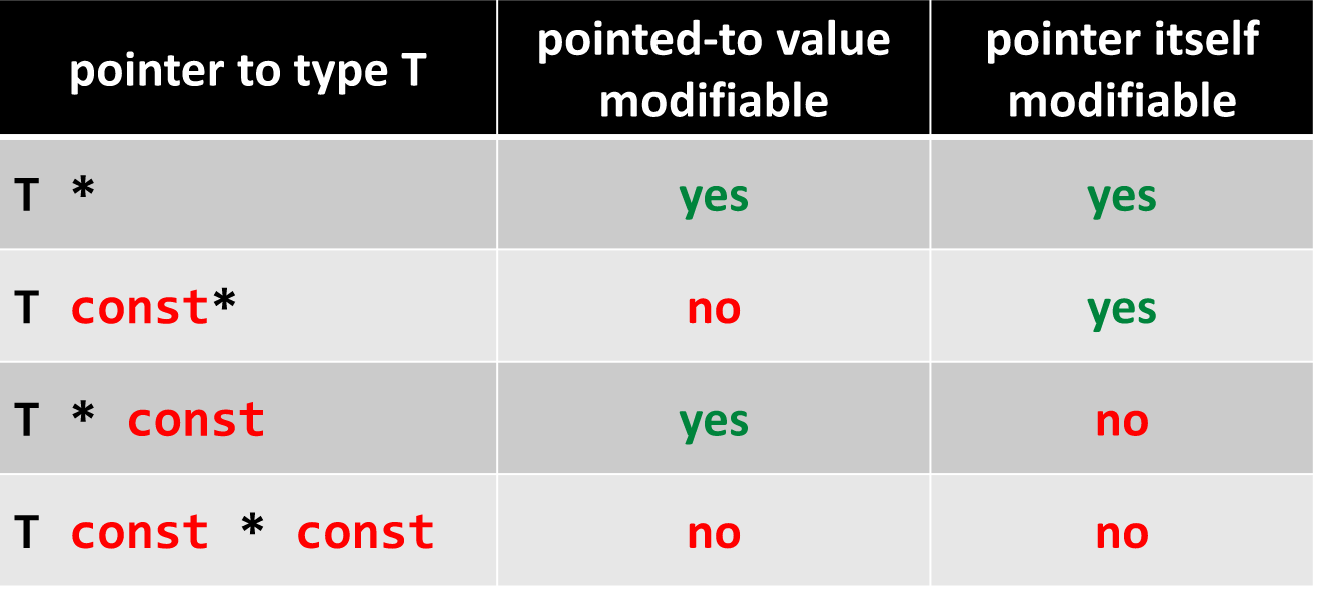
从右到左解释类型声明。
内存模型
heap: used for objects of dynamic storage duration;
空闲内存块列表。
stack: used for objects of automatic storage duration: local variables, function parameters, etc.
栈分配通常从高地址到低地址。

内存占用
基本数据类型的区别主要在于内存占用量。
sizeof(char); // 操作符: auto x = sizeof char
Integer Size Guarantees C++11
#include <cstdint>exact size:
int8_t,int16_t,int32_t,int64_t,unt8_t, …
动态内存分配
C++使用new和delete关键字进行动态内存管理。当使用new关键字为变量在堆上分配内存并返回内存地址,并自动调用构造函数进行初始化。如果分配内存失败,new返回nullptr或抛出异常。
nullptr为指针默认值(转换为false,可以用于逻辑判断)。
type *ptr = new type(args); // type *ptr = new type{args};
type *ptr = new type[const_num]{init_list};
delete ptr; // delete variable
delete [] ptr; // delete array
无法从指针类型判断其是只想单个变量或数组。
使用delete关键字对值为nullptr的指针进行操作不会出错;但使用delete对不是用new分配的内存块(栈)的指针进行操作将会出现不可知的结果;在使用delete释放内存后,再使用指针将会出现未知结果或导致程序崩溃。
In modern C++, manual allocation is actually only really necessary if you want to implement your own dynamic data structures / containers.
语法
定义变量
type varname;
定义可以与初始化结合。
type varname = value;
type varname = {value};
type varname{value}; // C++11: narrowing conversion ⇒ compiler warning
==基本数值类型变量在声明时不会被赋予默认值,其值是随机的。==
ClassName varname = ClassName(args); // 调用构造函数初始化变量
ClassName varname(args); // 简洁写法
ClassName varname = ClassName{args}; // c++11: narrow conversion
ClassName varname{args}; // 简洁写法
动态分配的变量返回变量的地址。
赋值
赋值运算默认具有值语义,即显式复制对象的数据成员,避免在非期望情况下修改数据;
-
避免将聚合类型变量的定义和初始化分开,否则则首先会调用默认构造函数执行初始化再随后执行赋值操作,造成额外开销。
-
==具有指针成员变量的类==应该重写赋值运算符和复制/移动构造函数,以处理动态分配对象的复制问题。否则,对已定义变量使用新构造对象赋值应注意,新构造对象仅具有临时生命周期,因此可能导致赋值后的变量中指针成员引用无效对象。
LinkedList l1; // LinkedList.header是指针成员变量 vector<int> v = {1, 2, 3, 4}; l1 = LinkedList(v); // 如果没有适当的赋值拷贝,由于临时创建对象释放,l1可能包含无效指针
引用语义
值语义(value semantics):赋值运算默认为值传递方式(包括函数输入输出参数)。
更接近数学记法:输入参数不会被函数改变;
we do not run into any memory management issues. No dangling references to nonexistent objects, no expensive and unnecessary free store allocation, no memory leaks, no smart or dumb pointers.
引用语义(reference semantics)
where you want to create an object, and let it live for a significant amount of time, and want different parties to modify the object, you need to pass by reference.
This is the case for globals like
std::coutthat need to be accessible from different places in the code, and it always has to be this very object at this very address.
指针:
they are objects that store values which are addresses in memory referring to objects.
at the higher level of abstraction passing and returning pointers to and from functions is usually considered passing by reference (reference semantics), even though technically you are passing values.
the reason people often resort to allocating objects in free store (on the heap) and returning a (more or less) smart pointer to it, is that value semantics does not play well with OO techniques that require access to objects via references or pointers to enable virtual function calls.
运算符
自增/自减
- prefix expressions
++x/--xreturns new (incremented/decremented) value; - postfix expression
x++/x--increments/decrements value, but returns old value;
逻辑运算
bool c = a && b; // false logical AND
bool d = a || b; // true logical OR
bool e = !a; // false logical NOT
Short-circuit Evaluation: The second operand of a boolean comparison is not evaluated if the result is already known after evaluating the first operand.
移位运算
只有整数类型能进行移位操作:
result = op1 >> op2 // 右移
result = op1 << op2 // 左移
其中op1是要进行移位的整数,op2是要偏移的位数。op1的值不会改变,移位的结果作为返回值,返回结果的类型与op1的类型相同(准确的说,返回类型应该是长整型,赋值的过程可以强制转换)。
如果op2=0,则实际不对op1移位;如果op2为负数或达到整数类型的bit长度,则结果未定义。实际测试(Windows/Linux)可以发现,移位运算会先对op2进行求余处理,使移位范围不超过整数的bit长度,再进行移位。
左移运算是逻辑移位,即右侧空出的位补零;如果op1是有符号数,则右移运算是算数移位,即左边空出的位填充符号位,如果op1是无符号数,则右移运算是逻辑移位,即左边空出的位补0。
控制流程
表达式(Expressions): series of computations (operators + operands); may produce a result.
Statements: sequence of expressions; do not produce a result; delimited by
;and grouped by{ }.
条件分支
if-else
if (condition1) {
// do this if condition1 is true
}
else {
// otherwise do this
}
// if(statement; condition) { … } C++17
else if是if嵌套在else语句块的结果。三元运算符:
condition ? true_statement : false_statement。
switch
switch (m) {
case 0: // do this if m is 0
break;
case 1:
case 3: // do this if m is 1 or 3
break;
default: // do this if m is not 0, 1 or 3
}
// switch (statement; variable) { … } C++17
Ternary Condition Operator
Result = Condition ? If-Expression : Else-Expression
循环
for (int i = 0; i < 5; ++i) {
cout << i << ' ';
}
std::vector<int> v {1,2,3,4,5};
for(auto i = begin(v); i != end(v); ++i) { cout << *i; }
for (int x : v) { cout << x << '\n'; } // c++11
while (j < 10) {
cout << j << ' ';
++j;
}
do {
cout << j << ' ';
--j;
} while (j > 0);
异常
try {...}
catch(std::invalid_argument&e){
throw; //re-throw exception
}catch(...){
// catch all exceptions
}
void funcname(...) noexcept {...} // throw exception not allowed
预处理命令
头文件
头文件用于集中存放函数原型声明和类型定义。
#include <filename>
按照标准方式搜索要包含的文件(将文件内容添加到当前处理的源文件中),该文件位于C++系统目录的include子目录下,一般要包含系统提供的标准文件时这样使用。
#include "filename"
首先在当前目录下搜索要包含的文件,如果没有,再按照标准方式搜索,*对用户自己编辑的文件,采用这种方式*。
宏
#define MACRO // 定义宏
#undef MACRO // 删除由define定义的宏
特殊宏
__LINE__; // 行号
__FILE__; // 文件名
__DATE__;
__TIME__;
__cplusplus; // 值为最新支持的c++标准发布时间
带参数的宏
#define LOG(x) std::cout << x << std::endl
条件编译指令
#if constant_expression
statements;
#elif constant_expression
statements;
#else
statements;
#endif
#ifdef identifier
statements;
#elif defined(identfier2)
statements;
#else
statements;
#endif
#ifndef identifier
statements;
#else
statements;
#endif
#ifdef和#ifndef用于判断一个宏是否已经定义,这两个命令常组合起来使用,在头文件中加入以下结构,用于防止头文件的重复包含。
#ifndef identifier
#define identifier
header_file_contents
#endif
#pragma once:保证在源文件中只会包含该头文件一次,避免类型的重复定义。
**注意:**不要在头文件中添加定义,因为该头文件如果被包含到不同源文件,在链接阶段会产生重复符号定义。
- 将函数声明为
static,但没有必要为每个源文件定义功能相同的函数; - ==将函数声明为
inline,则编译时函数体被替换为代码块==。
兼容C语言
使C++在编译C语言函数保持对C语言的兼容,在头文件中添加以下结构。
#ifdef __cplusplus
#if __cplusplus
extern "C"{
#endif
#endif
function-declare;
#ifdef __cplusplus
#if __cplusplus
}
#endif
#endif
注释
文档
C++ Docstrings
/**
* Create a new Triangle object of side lengths 1, 1, and 1.
* @brief Triangle class used for triangle manipulations.
* @details 细节
* @param a The Length of triangle side a.
* @return The length of side a.
* @see Triangle(const double a, const double b, const double c)
* @file 文件名
* @todo todo things
*/
/**
* @mainpage Triangle Library Documentation
* @author 作者
* @version 版本号
* @date 年-月-日
* @section intro_sec Introduction
* Do somethings ...
* @subsection install_dependencies Installing Dependencies
*/
doxygen
运行doxygen生成文档。
doxygen –g Doxyfile
Lei Mao's Log Book – C/C++ Documentation Using Doxygen
Doxygen Documentation Generator - Visual Studio Marketplace
函数
- encapsulation of implementation details
- easier reasoning about correctness and testing by breaking down problems into separate functions
- avoids repeating code for common tasks
返回类型推断:在编译期间可以确定返回类型。
auto foo (int i, double d) {
…
return i;
}
默认参数:
double f (double a, double b = 1.5) {
return (a * b);
}
函数声明(declaration):
- 告知编译器一个函数存在于某个源文件中。函数声明通常放置在头文件中,便于导入。
- 作为函数参数,接受声明类型的函数对象
int cmp(int &, int &);
参数传递
传入参数

Read from cheaply copyable object (all fundamental types) ⇒ pass by value;
Read from object with larger (> 64bit) memory footprint ⇒ pass by
type const &;Write to function-external object ⇒ pass by
type &.
可变参数列表
可变参数函数(如printf)的最后一个参数以“...”代替。
return_type func_name (param,...){...}
使用在“stdarg.h”中定义的类型(va_list指针类型)和宏(va_start、va_arg、va_end和va_copy)访问参数列表。
-
va_start:返回参数列表存储区的指针。使用可变参数列表必须至少提供一个占位的固定参数,这个参数可以不被函数使用。这样va_start才可以定位到参数列表的首地址。va_list ptr_args = va_start(param, param1); for(;ptr_args!=nullptr; ++ptr_args){ var_name = va_arg(ptr_args, type); } -
va_arg:返回一个参数。 -
va_end:将参数列表指针设为nullptr,等效标记为end。 -
va_copy: 将参数列表指针,赋值给另一个指针。
参数列表并没有显式的结束标识,因此在传递参数时,需要使用固定参数指定可变参数个数,或者使用特殊参数值标识参数列表结束。
传递数组作为参数
通过以上两种指针的定义及赋值,可以得知数组指针是有类型的,即数组指针的类型为:指明数组低维度长度的指针型变量,表示为:
type (*ptr_name)[N]...;
数组指针类型用于定义数组对象或==传递数组参数==。
数组也可通过引用类型传递,但必须显式指定数组长度,传递的参数必须与声明长度相同(否则产生编译错误)。
void print_array_ref(int (&array)[5]);
由于长度固定,难以通用。因此传递数组参数通常还是通过指针或容器对象(如std::vector和std::array)。
传递函数作为参数
函数指针:函数是特殊类型的对象,函数名是该对象的地址。可定义该函数类型的指针以引用该函数,并作为参数传递:
return_type (*ptr_func)(arg_types,...); // 定义函数类型时不需要形参名
ptr_func(arg_list); // => (*ptr_func)(arg_list);
函数指针可自动解引用,因此可以不添加
*运算符。
为了在定义函数参数时简化语法,可以预先定义函数类型:
typedef return_type (* FunctionType)(arg_types);
using FunctionType = return_type (*)(arg_types); // [c++11]
call_func(FunctionType call_func); // 传递函数参数
函数对象:
std::function<return_type (arg_types)> func_obj; // [c++11]
using func_type = std::function<return_type (arg_types)>;
返回值

返回多值:
==使用结构体来构造多返回值结构==。
使用
tuple和自动展开;std::make_pair(); // return tuple使用数组
std::array或向量std::vector(类型相同);==使用引用或指针类型输入参数作为输出参数==(可能产生歧义)。
可选参数
optional<int> x;
if (x) {} // x若未经初始化,则判断条件为false;代替传统使用空指针判断值是否可用。
函数重载
functions with the same name but different parameter lists.
如果一组函数具有相同的名称,但具有不同的输入参数模式(参数类型,参数个数,参数顺序),则这些参数可以同时存在于同一命名空间。重载(overload)就是在编译时通过传入参数的类型,来选择相应的函数。
不能通过访问权限、返回类型、抛出的异常进行重载。
对于继承来说,如果某一方法在父类中是访问权限是
private,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
运算符重载
运算符重载是对已有运算符赋予多重含义,使同一个运算符作用于不同类型的数据时导致不同的行为。运算符重载的实质是函数重载。
运算符可重载为独立函数或类的成员函数。运算符声明可能需要在相应操作数类定义中使用friend声明以访问操作数的非公开成员。
[friend] type operator op (params) { /*statements*/ }
op => +,-,*,/,[],++,--,...
重载为成员函数时:
- 对于单目运算符,则不需要参数;对于“++”和“--”,为了区分前置运算符和后置运算符,当重载为后置运算符是,增加一个整形参数,但该参数只用于区分,没有其它用途。
- 对于双目运算符,还需要将另一个操作数作为参数传入函数;
输出运算符
ostream& operator << (ostream& os, type T)
{ os << T.x << T.y; return os; }
比较运算符
C++使用值语义,因此比较运算符==,!=是比较对象的值。编译器不会自动为自定义类型生成比较运算符,需要自定义。
bool operator==(T1 const&, T2 const&)const=default; // c++20
=default:自动生成默认比较运算符(递归比较所有成员变量),无需给出函数原型;不用重载
!=运算符,编译器会自动根据==的定义生成!=运算符的定义。
c++20:compiler rewrites a calla == basb == aif necessary。
双目运算符的交换问题:双目运算符的运算数类型如果不同,需要声明不同的操作符重载,以满足定义的交换律。
优化
Return Value Optimization (RVO):在返回语句中构造对象时,将不会为返回值创建临时对象。
Type create_object(){
// ...
return Type(...) // Performing RVO
}
Type a = create_object();
由于类型在Stack上占用的空间在编译期间是确定的,因此编译器预先为返回值
a在Stack上分配空间(==相当于调用一个空的默认构造函数==)。通过修改函数原型以及函数行为,将该空间地址通过指针传递给调用函数,在返回语句构造对象时使用传入地址指定的空间,而非重新在Stack上分配一段内存空间。当函数执行完成时,将上述预分配空间的地址绑定到返回值。整个过程仅执行一次对象构造,而为执行优化时,将执行一次构造函数和两次复制构造函数(从局部对象到临时对象,从临时对象到返回值,临时对象实际也是在调用对象前通过指针传入函数)。
Named Return Value Optimization (NRVO):在返回语句中返回局部对象,将不会为返回值创建临时对象。
类似地,NRVO则是在要返回的局部变量在构造时,使用上层传入的Stack空间。
内联(inlining):Calls to small/short functions are replaced with the code of the function.
Inlining is a lot harder or sometimes impossible in many other languages like Java, C#, etc. with always-on polymorphism which means that all/most function/method calls can only be resolved at runtime.
主函数
#include <iostream>
int main (int argc, char* argv[]) {
for(int i = 0; i < argc; ++i) {
std::cout << argv[i] << '\n';
}
} // return 0 by default only for main function
- names
argcandargvare only a conventionargv[0]contains the program call
匿名函数
lambda class
编译器自动生成的函数对象,用于需要提供函数作为参数的位置。
[](P const& x, P const& y){ return x.c < y.c; }
[](auto x){ ... } // c++14
[](auto const & x){ ... }
[](auto &x){ ... }
输入参数为空则可以省略
()。
closure
instance of lambda class。
保存外部作用域的变量:
[=](...){...} // captures all by value
[&](...){...} // captures all by reference
[=x,&y](...){...} // captures x by value and y by reference
[= ,&y](...){...} // captures all by value except y by reference
保存闭包:闭包类型由编译器确定,因此使用auto表示结果。
auto f = [...](...){...}
聚合类型
将多个基本类型变量组合成一个聚合类型,相当于一个简单类型,成员变量根据声明顺序在内存中连续存储。
聚合类型是对逻辑上相关的函数和数据的封装,是对问题的抽象描述。提供成员访问限制,自定义初始化、解构、复制和赋值,成员函数;保证类行为的不变性、清晰性和正确性。
结构体
struct point {
int x; // ← "member variable"
int y;
};
point p1 = {10, 5};
point p2 {5, 10}; // c++11
- semantic data grouping:
point,date, …- avoids many function parameters and thus, confusion
- can return multiple values from function with one dedicated type instead of multiple non-const reference output parameters
类
class ClassName: public classA,…, protected classB,…, private classC,…
{
public: //外部接口
//构造函数
ClassName()=default;
[explicit]ClassName(args1, arg2,...){ /*initialization;*/}
virtual ~ClassName();//(虚)析构函数
//数据成员;
using value_type = std::uint64_t; //类型接口
//函数成员;
type func_name(params){}
private:
protected://保护成员
};
在C++中,
class和struct关键字都可用于定义类,不同之处在于两者的默认访问权限不同(class是private,struct是public)。Do not use leading underscores or double underscores in names of types, variables, functions, private data members.
继承语法:访问修饰符指明基类成员的访问方式,如果不显式给出,则默认为私有继承。
组合类:一个类的成员不仅包含基本数据类型,还包含其它类的对象。
成员变量
常量成员变量
==如果对象被声明成常量,那么限定只能调用对象的常成员函数以防止对象被修改。==
一般常量必须在声明时进行初始化,在C++的类中,常数据成员的初始化,在构造函数的初始化列表中完成,而不能在声明时初始化(C++11支持声明时初始化),或在构造函数的函数体中进行初始化。
静态成员变量
如果某个属性为整个类所共有,不属于任何一个具体对象,则采用static关键字声明为静态成员变量。静态成员在每个类中只有一个实例,实现同一类的不同对象之间的数据共享。
类内部只是静态成员的声明,静态成员(包括常量)需要在程序的全局作用域的某个位置对其进行定义和初始化。
由于类的静态成员变量在头文件中声明,其作用域为全局作用域而非文件作用域。因此需要将初始化放在某个源文件中,而不能放在头文件中;否则当头文件被多个源文件引用时,会分别执行多次定义产生符号冲突。
type class_name::static_var = value;
整数静态常量比较特别,可以在声明时进行初始化。
资源管理
构造函数
构造函数的函数名与类名相同,且没有返回值,被声明为公有函数。如果类中没有声明构造函数,或给出了无参构造函数的声明但没有给出实现,则编译器会自动生成一个默认的构造函数,不做任何事情;如果用户自定义了构造函数,则不会再自动生成默认构造函数,如果没有另外声明无参构造函数,则必须在声明对象时,提供必要的参数完成初始化。
尽可能避免书写特殊成员函数,除非需要资源分配。使用成员初始化器可以执行默认初始化,使用智能指针、容器等可以尽量减少人工管理内存分配,从而避免自定义析构函数。
初始化列表构造函数
初始化列表initializer_list是一种特殊可迭代容器,用于序列类型的初始化。
#include <initializer_list> // c++11
ClassA{ ClassA(std::initializer_list<int> li){...} }
ClassA a {1,3,4,5}; // {}调用初始化列表构造函数,而()调用其他构造函数
复制构造函数
复制构造函数是一种特殊的构造函数,具有一般构造函数的所有特性,其形参是本类对象的引用,其作用是使用一个已经存在的对象,去初始化一个同类型的新对象。如果没有在类中定义复制构造函数,则编译器会生成默认的复制构造函数,其功能是:把参数对象的每个数据成员的复制到新建立的对象中(如果声明了复制构造函数,则复制功能由复制构造函数完成,类将不会自动复制相应的变量)。
ClassName(const ClassName & obj); //复制构造函数
ClassName(const ClassName & obj)=delete; //禁用复制构造函数
浅拷贝:C++默认是值语义,因此进行赋值运算时,会复制类的所有成员,但使用原始指针引用的对象不会被复制(弱引用关系,不属于该类的成员)。==自定义复制构造函数和赋值运算符可以定义是否为指针引用的对象创建副本==。
Object(const Object& other){ // 默认复制类的成员
memcpy(this, &other, sizeof(Object))
}
复制构造函数的调用情况:
-
当用类的一个对象去初始化该类的另一个对象。
-
如果函数的形参是类的对象,调用函数时,用实参初始化形参。
-
如果函数的返回值是类的对象,函数执行完返回时,为了完成从子函数到主函数的值传递,创建一个临时对象,初始化该对象。
如果类不包含动态分配的资源,则一般使用默认的构造函数就足够了。 一般情况,每个对象所拥有的资源应该是相互独立的,这样一个对象的操作才不会影响到另一个对象。 但是使用默认复制构造函数,只能完成成员变量即相关资源的标识符的复制,而不能自动完成动态资源的分配。 这时候就需要程序定义复制构造函数,来完成动态分配资源的分配和值的复制。
“=”操作符的意义在于使用一个对象向另一个同类型对象赋值,这和初始化时使用一个对象对同类型对象进行初始化的原理基本相同。
“=”操作符的处理==可能还需要先释放对象已分配的资源==,再申请新的资源。
如果没有定义“=”操作符,则会自动生成一个与默认复制构造函数具有相同功能的操作符定义,因此,默认的“=”操作符并不能完成具有动态资源的对象的复制。
通常,定义了复制构造函数也就意味着需要定义“=”操作符。
ClassName& ClassName::operator = (ClassName const&);
https://en.cppreference.com/w/cpp/language/copy_constructor
移动语义
将对象在堆上的空间与新对象进行交换(新对象可能并未分配堆空间)。
std::swap(a,b);
移动构造函数和移动赋值函数
ClassName(const ClassName && obj); //移动构造函数
ClassName& ClassName::operator = (ClassName const&&); //移动赋值运算符
https://hackingcpp.com/cpp/lang/move_semantics.html
初始化
Resource Acquisition Is Initialization (RAII)
- acquire some resource (memory, file handle, connection, …) when object is constructed
- release/clean up resource when object is destroyed (de-allocate memory, close connection, …)
对象所占据的内存空间只是用于存放数据成员,函数成员不在每个对象中存储副本。但是如果该类包含虚函数,则虚函数地址存放在虚函数表中,将占用内存空间。
成员初始化列表
通过构造函数的初始化列表对成员变量进行初始化(构造)。==初始值可以来自构造函数的参数。====初始化列表也可以调用本类的其他构造函数代替单独变量初始化。==
class Foo {
int i_; // 1st
double x_; // 2nd
public:
Foo(): i_{10}, x_{3.14} { } // same order: i_ , x_
Foo(int i, double x): i_(i), x_(x) {}
};
成员初始化列表:使用
()或{}(C++11: narrowing conversion)传递参数。
初始化列表应首先给出父类的初始化声明,再给出当前类中成员变量的初始值(初始化顺序与成员的声明顺序保持一致)。构造函数执行的次序:
-
调用父类的构造函数初始化父类成员,顺序与继承声明一致(从左到右);
-
初始化基本类型或调用成员的构造函数,调用顺序与内嵌对象在类中声明的次序一致;
当未在初始化列表给出成员的初始化声明,则会调用该类型的默认构造函数(此时该类型需要具有默认构造函数)。而如果在构造函数体内对该成员通过赋值进行初始化,则会重复执行构造,造成性能开销。==因此应该优先使用成员初始化列表。==
-
执行构造函数体的内容。
隐式类型转换
只有一个参数的构造函数,其调用形式与强制类型转换的语法相同,因此,等效于同时重载了由指定类型到当前类型的(隐式)类型转换运算符。
type y;
ClassName x = y; // => 隐式转换:className x = ClassName(y);
当构造函数被
explicit关键字修饰时,则不会同时重载该运算符,因此上述代码不会进行隐式转换,从而赋值语句类型不兼容。
初始化器
C++11支持在声明成员变量时给出默认初始值。
class Foo {
int i_ = 10;
double x_ = 3.14;
};
析构函数
析构函数与构造函数的作用基本相反,用来完成对象被删除前的一些清理工作,在对象的生命期即将结束时被自动调用。和构造函数不同的是,析构函数不接受任何参数,但可以是虚函数。声明虚析构函数必须给出实现(参考虚函数)。
析构函数调用顺序由类的继承关系决定,与构造函数的调用顺序相反:即类本身的析构函数,类成员对象的析构函数,基类的析构函数。由于析构函数是自动调用的,因此无需显示调用父类析构函数。
成员函数
成员函数可以在类的声明之外单独定义(使用作用域限定符),在类声明中仅给出声明。
type ClassName::func_name(params){}
代码量较小的函数应该尽量放置于类定义中,以方便“内联”优化。
How to implement a feature / add new functionality?
- only need to access public data (e.g. via member functions) ⇒ implement as free standing function
- need to access private data ⇒ implement as member function
==use "action" functions instead of just "setters"==:usually models problems better; more fine-grained control; better code readability / expression of intent
在成员函数中访问成员变量/函数:
this指针
非静态成员函数的参数隐含了当前实例的指针this。
如果在Class的成员函数中没有可见的同名局部作用域标识符,那么在该函数内可以直接访问成员Member。反之,非静态成员需要通过this指针进行访问this->Member。
也可以使用作用域限定符
::访问类成员,通常作用域限定符用于访问静态成员,而实例成员通过this指针访问。
此外,this指针还可以用于在类内部调用需要该类指针的函数。
成员运算符
当运算符的第一个参数是自定义类型,可将该运算符定义/重载为自定义类的成员。
当第一个参数不是自定义类类型,则重载为独立运算符。也可将独立运算符在类内部以
friends修饰以确保其能访问类的内部数据。
类型转换运算符
类型转换函数用于自动==将类对象转换成其他兼容类型的对象==,从而实现类似基本数据类型隐式转换的功能。类型转换函数通过重载“(...)”操作符实现:
public operator type(); // 定义方法将当前类型转换为type
该函数原型比较特别,没有返回值,也不需要提供参数。但是函数结束前必须返回type类型的值。
指针转换运算符是为了方便对自定义模板类的指针进行强制类型转换而重载的,因为系统不能直接把自定义类的指针强制转换成基本类型的指针。指针转换运算符的重载函数比较特殊,它没有返回值(连void也没有)。
函数对象
重载()运算符的类。 ==函数对象可以通过私有变量保存内部状态==。
public type operator (args); // 注意函数原型与类型转换运算符的区别
obj(args); // 调用()重载的函数。
成员引用运算符*
当一个类封装另一个类对象或指针时(例如智能指针),如果要透明访问被封装类的成员,可以重载->运算符(普通版本以及常量版本):
InternalObject* operator->(){ return prt_obj;}
ExternalObject* m = new ExternalObject();
m->some_interal_member;
“=”和“[]”运算符
这两种运算符的适用场合,有可能作为表达式的左值出现,如
A[5]=2;
(a=b)++;
作为左值的量都必须是变量,否则无法进行赋值或自加等操作,这就要求在重载“=”和“[]”运算符时返回变量;由于函数的返回值是一个右值(临时变量),所以不满足要求。
所以在重载这两个操作符时,返回值应该是引用类型。当然,由于局部变量在函数结束时就消失了,所以不能返回局部变量的引用,否则对引用的操作将出现错误。
“=”返回左操组数(上面例子中a)的引用;
“[]”返回左操作数(上面例子的A)的索引对应项的引用。只能重载一维数组下标操作符(如何重载多维下标http://blog.sina.com.cn/s/blog_66ec4d660100mxq5.html)。
静态成员函数
static type static_function_declare();
class_name::static_function(); // 调用静态成员函数
静态成员函数只能访问类的静态成员函数/变量。
常量成员函数
type member_function_declare() const;
const可以用于修饰函数的返回值,表示对函数的返回值不可以做修改。
使用const关键字修饰成员函数,意味着成员函数具有“只读”属性,而不能修改对象(实例成员变量)或者调用任何非常成员函数。
使用
mutable修饰的成员是例外,可以被const方法修改。
const可以用于成员函数的重载(在声明和定义处都需要使用const修饰),当对象被声明成常量时,则该实例只能访问使用const成员函数,因为只有这样才能保证类的成员变量不会被修改。
对于一般对象,则常函数成员和非常函数成员都可以被调用。
当对象是变量时,优先调用同名非常成员函数(当没有声明非常成员函数时,调用同名常成员函数)。
const-qualify all non-modifying member functions。
访问静态成员
静态成员不与类的实例绑定,需要通过作用域限定符和类名进行访问。
ClassName::StaticMember;
ClassName::StaticMemberFunction(args);
访问限制
在类内部,所有的数据成员的为其成员函数所共享;通过静态数据成员,实现同一类的不同对象之间的数据共享。
访问关系是针对于类而言的,并不是针对类的实例。即对象的成员函数可以访问同一类型对象的所有成员变量。
访问控制的主要作用是限定代码的组织方式,对程序运行没有影响;实际上可以通过操纵指针绕过访问控制限制。

Friends
class A{…… friend class B; …… } // friend class
class A{…… type function(args); …… } // friend function
友元函数是在类中用关键字friend修饰的非成员函数,可以是普通函数也可以是其他类的成员函数,虽然它不是本类的成员函数,但是可以访问本类的私有和保护成员。
**友元关系是不能传递的:**A是B的友元,B是C的友元,如果没有声明,A和C是没有友元关系的;
**友元关系是单向的:**A是B的友元,如果没有声明,则B不是A的友元;
**友元关系是不被继承的:**如果A是B的友元,但A的派生类,如果没有声明,则不是B的友元。
自定义类型
https://hackingcpp.com/cpp/design/arithmetic_types.html
https://hackingcpp.com/cpp/design/node_based_data_structures.html
程序结构
命名空间
- 避免命名冲突;
- 将内容分为不同的部分。
命名空间仅用于防止命名冲突,不具有访问控制作用(访问控制修饰符修饰命名空间无效)。
定义
namespace my{
class vector {...};
namespace time{...}
}
一个文件中可以定义多个命名空间;同时,一个命名空间也可以出现在多个文件中。
命名空间可嵌套定义。
引入命名空间
my::vector v1;
using my::vector; // 单独引入命名空间中的定义
vector v2;
using my; // 引入命名空间中的所有定义
namespace mt = my::time; // 定义命名空间别名简化书写
避免在头文件中引入命名空间:引入命名空间会导入其中所有的声明到头文件中。该头文件再被其他文件引用时,可能造成命名冲突。
标识符作用域
-
局部作用域:在代码块中声明的标识符,其作用域从声明处开始,一直到块结束的大括号为止。**具有局部作用域的变量也称为局部变量。**函数体、控制语句块,空语句块等都是局部作用域。
-
类作用域:类
Class的成员Member具有类作用域,其范围为类的定义。 -
文件作用域:具有文件作用域的标识符其作用域开始于声明点,结束于文件尾。具有文件作用域的变量也称为全局变量。
命名空间将文件作用域进行了逻辑划分;
可见性
程序运行到某一点在,能够引用到的标识符就是该处可见的标识符。作用域可见性的规则:
- 标识符声明在前,引用在后;
- 在同一作用域中不能定义同名标识符;
- 在没有互相包含关系的不同作用域中定义的同名标识符,互不影响;
- 如果在两个或多个具有包含关系的作用域中声明了同名标识符,则外层标识符在内层不可见。
作用域限定符
用于在默认规则不可见的位置访问某些标识符。
- 访问命名空间中的成员(例如
std::cout); - 在类定义外部,定义函原型和初始化静态变量;
- 访问静态成员;
- 在类内部,识别多继承的同名成员;
对于静态成员,则通过作用域分辨符::进行访问:ClassName::M。
多继承的父类成员可见性。
前向声明
两个类不能相互引用作为其定义的一部分,因为这样无法确定任何一个类的类型。但是两个类可以相互引用其指针作为定义的一部分。
如果出现以上相互引用的情况下,一般地,应该互相包含其头文件,但这样又会造成头文件内容无法确定。为了解决这一问题,C++引入了前向声明,即==在定义类之前对类名进行声明==,则无需包含该类定义所在的头文件,即可定义该类的指针。
class c_a;
class c_b{
c_a *p_a;
}
多态
继承
类的继承,是新类从已有类那里得到已有的特性。同时,从已有类产生新类的过程就是派生。由原有类产生新类时,新类便包含了原有类的特性,同时也可以加入自己所有的新特性。
从对象的数据存储来看,组合类和派生的作用一样:如果把派生类的父类的实例都添加到一个新类的定义中,则派生类的这个新类有相同的数据成员,只是组织形式不同。但是组合类只能利用现有类提供的功能并在新类中定义新功能,而派生类在此基础上可以提供多态行为,即子类可以通过虚函数覆盖父类的同名函数。反之,如果不需要更改父类行为,使用组合类更简洁。
构造/析构函数
根据构造函数调用规则,应该在子类的初始化列表中调用父类构造函数。
虚继承
成员函数重载
运算符重载
覆盖
具有相同函数原型(即相同的函数名与输入参数列表)的函数不满足重载的条件,不能存在于同一命名空间。但具有相同原型的函数可存在于父类(接口)与子类(实现)中。子类(实现)提供的具有相同原型的函数是对父类(接口)的相应函数进行重定义,以替换原有的功能,这种方式称为覆盖(override)。
隐藏
当子类中定义与父类同名函数时,将无法直接访问父类的同名函数(即使非重载形式)。此时需要使用父类指针(在类外部)或作用域限定符(类内部)访问父类函数。
多继承情况下,如果继承多个父类的同名函数,也会导致父类同名函数的隐藏。
虚函数
对于从同一父类派生出的不同类的对象,如果使用==父类的指针==统一进行管理与访问,可以明显的简化程序。但使用父类指针引用子类对象只能访问到父类中定义的成员,而不能访问子类中的成员。如果需要使用父类的指针访问子类中的成员函数,就需要首先在父类中将该函数声明为虚函数(不能通过父类指针访问子类数据成员)。
虚函数是动态绑定的基础,虚函数必须是非静态的成员函数,虚函数经过派生后,在类族中就可以实现运行过程中的多态。虚函数的声明语法:
virtual type function_name(arg_list); // in parent class
type function_name(arg_list)override {statements} // in child class
[1] C++ 虚函数表解析. http://blog.csdn.net/haoel/article/details/1948051/。
虚函数的修饰符只能出现在类中函数声明处,而不能在函数实现处。在子类中不需要显式地给出虚函数的声明,当子类的成员函数满足重载条件时就会自动确定为虚函数。被覆盖的父类函数,任然可以通过作用域标识符来访问。
虚函数的适用条件
当子类需要修改父类的行为时,就应该将父类的相应函数声明为虚函数。而父类中声明的非虚函数,通常代表那些不希望被子类改变的功能,也是不能实现多态的。因此一般不要重写继承而来的非虚函数(虽然语法没有限制)。
在重写继承来的虚函数时,不能改变函数的默认形参值,因为:虽然虚函数是动态绑定的,但是默认形参值是静态绑定的。
虚函数必须给出实现,否则应该声明为纯虚函数。
虚析构函数
使用父类指针访问子类对象完成后,如果子类对象是动态分配的,这时存在的一个问题是:能否直接delete父类指针,完成子类对象的删除。在动态分配内存时,系统会记录下所分配的内存的首地址和分配长度,因此在执行删除操作时,无论指针指向的是父类对象还是子类对象,都能够正确的释放对象所占用的内存。
但是如果动态创建的对象中还有指向动态分配的内存空间的指针成员,则这样的删除就是不完全的,因为这些指针成员指向的动态分配的内存空间并不能得到释放(如同深拷贝与浅拷贝的原理一样,在构造函数中,浅拷贝只会复制指针,而不会另外增加一份指针指向的内容,这时需要深拷贝手动完成内容的赋值)。
动态空间的释放显然应该由析构函数来完成,其中父类的构造函数释放父类对象动态申请的内存空间,子类的构造函数释放子类对象动态申请的内存空间。当使用父类指针来实现多态时,由于通过父类指针只能直接访问父类成员,析构函数也是一样,这种情况下访问不到子类的析构函数(对象通过delete销毁获声明周期结束时,只会调用父类的构造函数),则不能完成子类动态分配空间的释放,因此要将父类的析构函数声明为虚函数。
抽象类
抽象类用于抽象和设计接口。一个抽象类无法实例化,只能通过继承将抽象类改写为非抽象类,然后再实例化。可以定义抽象类的指针和引用,通过指针和引用,就可以访问子类的对象,实现多态性。
纯虚函数
抽象类是带有纯虚函数的类。抽象方法、接口。
virtual tpye function_name(args...) = 0;
抽象类派生出新类后,如果子类中给出了所有纯虚函数的函数实现,这个子类就不再是抽象类,而可以实例化;反之,如果子类中没有完全给出所有纯虚函数的实现,那么这个子类就仍然是抽象类。
模板
模板定义语法
template <typename T,..., args> declaration;
其中,declaration可以表示函数或类的声明语法。模板参数包括:
-
类型参数,使用类型定义关键字(
class或typename)或者嵌套定义的类模板类型(template <typename T,...>ClassName); -
非类型参数,参数类型可以是整数,枚举,指针,引用或指向成员的指针,且==在编译时可以确定为常量==(类似于数组长度)。
模板参数可设置默认值。
编译器根据模板生成实际代码:定义模板并不定义实际类型或函数,只有在使用模板并传递相应的参数时,编译器才真正添加一个类型或函数。
函数模板
函数模板的声明语法:
template <typename T1, typename T2,...>
T2 function_name(T param,...){statements}
类型参数用来指定函数模板的参数类型和返回值类型,以及声明函数中的变量类型等。
实例化
fucntion_name<T>(args); // 可省略类型参数,当类型可由参数推导出
类模板
使用类模板使用户可以为类声明一种模式,使得类中的某些数据成员,某些成员函数的参数、返回值能取任意类型(包括系统预定义的和用户自定义的)。类模板的定义语法:
template <typename T1, typename T2, ..., int n,...>
class ClassName{member_declaration}
在类模板内部定义成员的方法与普通类成员的定义语法一样,可能用到模板参数表中定义的类型或数值参数。模板类成员可以是静态或非静态,数据或函数成员。
如果要在类模板定义范围以外定义其成员函数,则必须指定其所属的模板类,且模板类要指定相应的模板参数,即采用以下定义形式
template < class T1,class T2, ..., int n,...> T2 ClassName<T1,T2,...,n...>::functionname(arg_list){statements}静态数据成员的定义方法也类似。
类模板的成员函数也可作为函数模板来定义,即增加额外的模板参数,其声明和定义语法如下所示。
template <typename A1,...>
class ClassName(args_list){
template<typename T1,...>
T1 function_identifer(A1 param1, ...){statements}
}
==(在类中的声明形式与一般函数一致),而不能如普通类一样,将成员函数的实现放到源文件中(否则或出现链接错误,LINK2019/2001)==。
类模板实例化
使用一个模板类建立对象时,应该按以下形式声明:
ClassTemplate<T1,T2,...,n,...>obj1;